Predict missing values (Tutorial)#
Note
This is the Predict missing values tutorial. The Predict missing values documentation is available here.
With Simple ML for Sheets, also referred to as Simple ML, everyone can use Machine Learning (ML) in Google Sheets without knowing ML, without coding, and without sharing data with third parties.
This tutorial takes you through the steps of using Simple ML for Sheets to predict missing values in your data in a spreadsheet.
Prerequisites#
This tutorial is easier to follow if you are familiar with Google Sheets. For example, make sure you know the basics like how to select columns or set a cell value.
What you will learn#
How to install Simple ML for Sheets.
How to use Simple ML to predict missing values in your data.
Install Simple ML for Sheets#
First, install Simple ML for Sheets.
Go to Simple ML for Sheets in Google’s Marketplace and click the Install button.

Validate the permission request. Simple ML stores your machine learning models in your Google Drive in the
simple_ml_for_sheetsdirectory.Make a copy and open our spreadsheet with example data.
In the Google Sheets, open Simple ML for Sheets in the Extensions menu. If it is not visible, wait a few seconds and refresh the page. The addon can take up to a minute to appear after being installed.
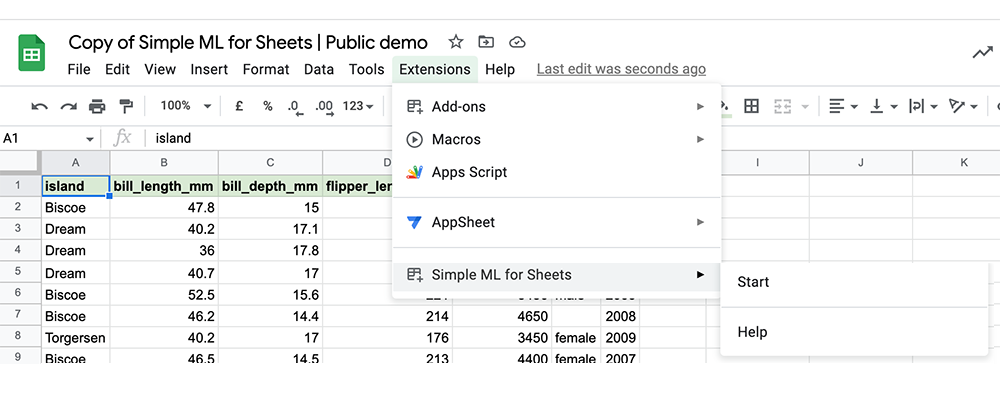
Predict missing values#
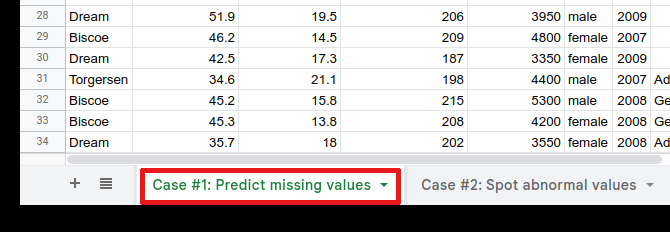
If you have not done it already, make a copy of the tutorial sheet.
Open the first tab called “Case #1: Predict missing value”.
Scenario#
You are studying a colony of penguins in Antarctica. This colony is composed of three penguin species: Chinstrap, Gentoo, and Adelie.

Image by Allison Horst
You are studying the differences between these species. Your colleague has collected physiological measurements (such as size and weight) of approximately 300 penguins. However, they got distracted in the process, and they forgot to note the species of 30 penguins.
You want to use Simple ML to recover the species of those 30 penguins.
Scroll up and down through the data.
This sheet contains data about penguins. Each row represents a penguin while each column represents a physiological aspect of the penguin.
The last column called
speciesrepresents the species of the animals. The species is missing for the first 30 rows.Open Simple ML. In the menu, click on Extensions > Simple ML for Sheets > Start.
Wait for the Simple ML side panel to appear (It might take a few seconds).
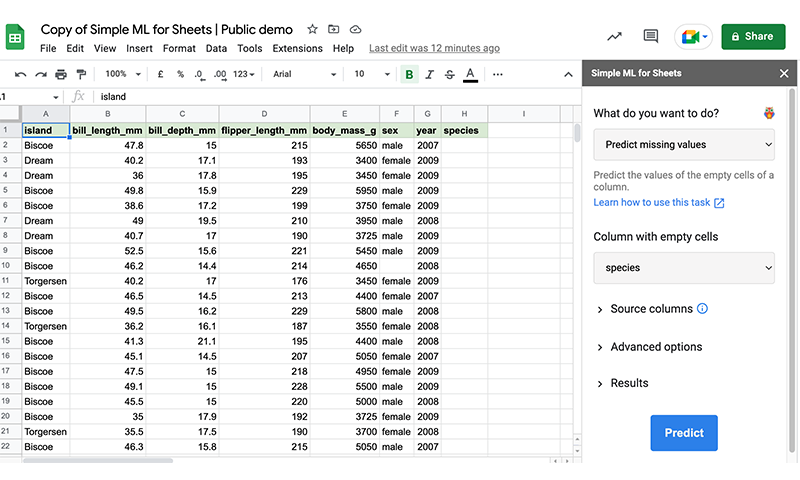
Predict Missing values#
Once Simple ML is loaded, you can use it to predict missing values.
First, notice that some rows are missing values in Column H,
species.In the Simple ML for Sheets side panel, make sure to click on Predict missing values. If you don’t see the main menu, click on the arrow in the upper left of the sidebar.

In the “Column with empty cells” section, select the column
species. This is the column that contains the missing values you want to predict.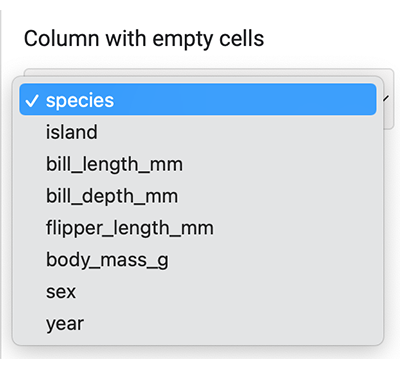
Click the Predict button.

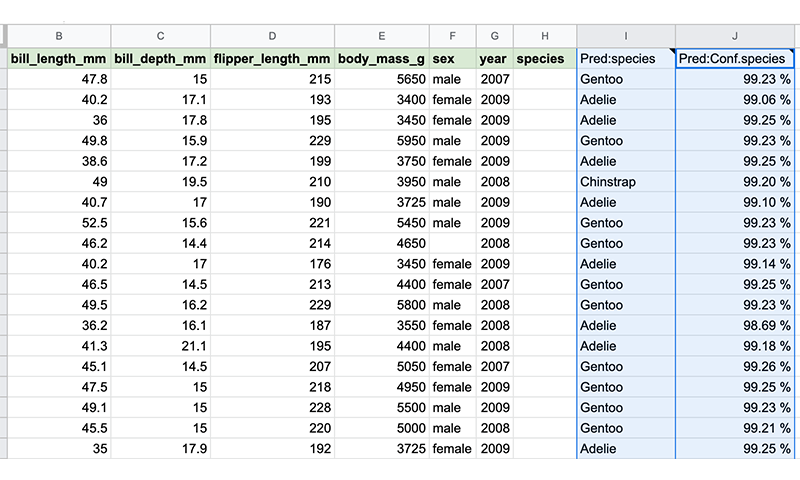
After a few seconds, two new columns appear:
Pred:species are the predicted values for the species column.
Pred:Conf.species are the confidences of the predicted value. In other words, this column indicates how confident the model is about the predictions in the column Pred:species. Confidence is a percentage between 0% and 100%, where 100% means that the model is sure of its prediction.
Some questions for you#
Look at the predicted values of species. Do they look reasonable to you?
Feel free to experiment with predicting missing values in other columns.
For the ML experts
Behind the scenes, the task Predict missing value collects rows with
species values and uses those rows to train a model. This model is then
applied to the rows with missing species values. The model is available in the
Manage models task and in the folder simple_ml_for_sheets of your Google
Drive.